Ixsight is looking for passionate individuals to join our team. Learn more


Ixsight is looking for passionate individuals to join our team. Learn more

In the data-driven landscape of 2026, where organizations process petabytes of information daily to fuel AI models, predictive analytics, and real-time decision-making, the adage "garbage in, garbage out" has never rung truer. Shockingly, poor data quality is estimated to cost the global economy $3.1 trillion annually, with individual businesses losing up to $15 million per year due to inaccurate or incomplete datasets. These losses manifest in misguided strategies, flawed AI outputs, and eroded customer trust issues that could be mitigated with the use of advanced data cleaning software that ensures reliable, accurate datasets for downstream systems such as AML software.
As businesses grapple with exploding data volumes from IoT devices, social media, and hybrid cloud environments, data cleaning tools have evolved into indispensable allies, leveraging AI and automation to transform messy raw data into pristine, actionable intelligence.
Data cleaning, often synonymous with data cleansing or scrubbing, is the systematic process of detecting, correcting, and removing errors from datasets to enhance their reliability. But what exactly does this entail in 2026? This comprehensive guide demystifies what data cleaning is, explores its pivotal role in modern operations, and spotlights the best data cleansing tools dominating the market. We'll delve into the data cleaning process, review top data cleaning software options with pros, cons, and real-world applications, and forecast trends shaping the future. Whether you're a data analyst battling Excel spreadsheets or a CIO overseeing enterprise pipelines, mastering data cleansing tools is key to unlocking data's full potential. Let's dive in.
At its essence, data cleaning is the meticulous process of identifying and rectifying errors, inconsistencies, and inaccuracies within datasets to ensure they are accurate, complete, consistent, and usable for downstream applications like analytics, machine learning, or reporting. Unlike mere data entry fixes, data cleaning addresses systemic issues such as duplicates, missing values, outliers, formatting discrepancies, and structural anomalies that arise from diverse sources, such as manual inputs, API integrations, or legacy migrations. In 2026, with AI's proliferation, data cleaning has transcended manual drudgery, incorporating intelligent algorithms - tools like Scrubbix that not only spot but predict and preempt data quality pitfalls.
To illustrate, consider a retailer's customer database riddled with variant spellings ("Jon Smith" vs. "John Smyth"), incomplete addresses, and phantom duplicates from merged CRM systems. Without data cleaning, marketing campaigns misfire, inventory forecasts falter, and personalization efforts flop. The process ensures uniformity, standardizing date formats from "MM/DD/YYYY" to ISO 8601 or normalizing phone numbers while preserving data integrity. It's not a one-time event but an iterative cycle, often embedded in ETL (Extract, Transform, Load) pipelines for ongoing hygiene.
Key components of data cleaning include:
In the AI era, data cleaning is foundational for model training; biased or noisy data leads to skewed predictions, amplifying risks in high-stakes sectors like healthcare or finance. As per industry benchmarks, clean data can boost analytics accuracy by 30-50%, underscoring why data cleaning tools are non-negotiable for 2026's data-centric enterprises.
In an era where 90% of the world's data was created in the last two years alone, data cleaning isn't optional; it's the bedrock of trustworthy insights and competitive edge. Poor data quality plagues 95% of organizations, leading to misguided decisions that cost an average of $12.9 million yearly per company, according to recent surveys. For businesses, this translates to tangible pains: faulty customer segmentation erodes marketing ROI, erroneous financial reports trigger compliance fines, and unclean training data hampers AI efficacy, resulting in models that underperform by up to 20%.
The importance of data cleaning amplifies in the 2026 context. With real-time data streams from edge computing and generative AI demanding instantaneous processing, unaddressed errors cascade into systemic failure, such think autonomous vehicles misreading sensor data or e-commerce platforms recommending irrelevant products. Clean data fosters reliability: it enhances decision-making by providing a single source of truth, streamlines workflows by reducing rework (which consumes 20-30% of analysts' time), and bolsters compliance with regulations like GDPR or CCPA, where data accuracy is paramount.
Moreover, data cleaning drives innovation. High-quality datasets supercharge machine learning, enabling predictive maintenance in manufacturing or personalized medicine in healthcare. Organizations with mature data quality practices report 5-10x faster analytics cycles and 15-20% higher revenue growth. Ethically, it mitigates biases, promoting fair AI outcomes. In sum, data cleaning transforms data from a liability into an asset, ensuring agility in volatile markets.
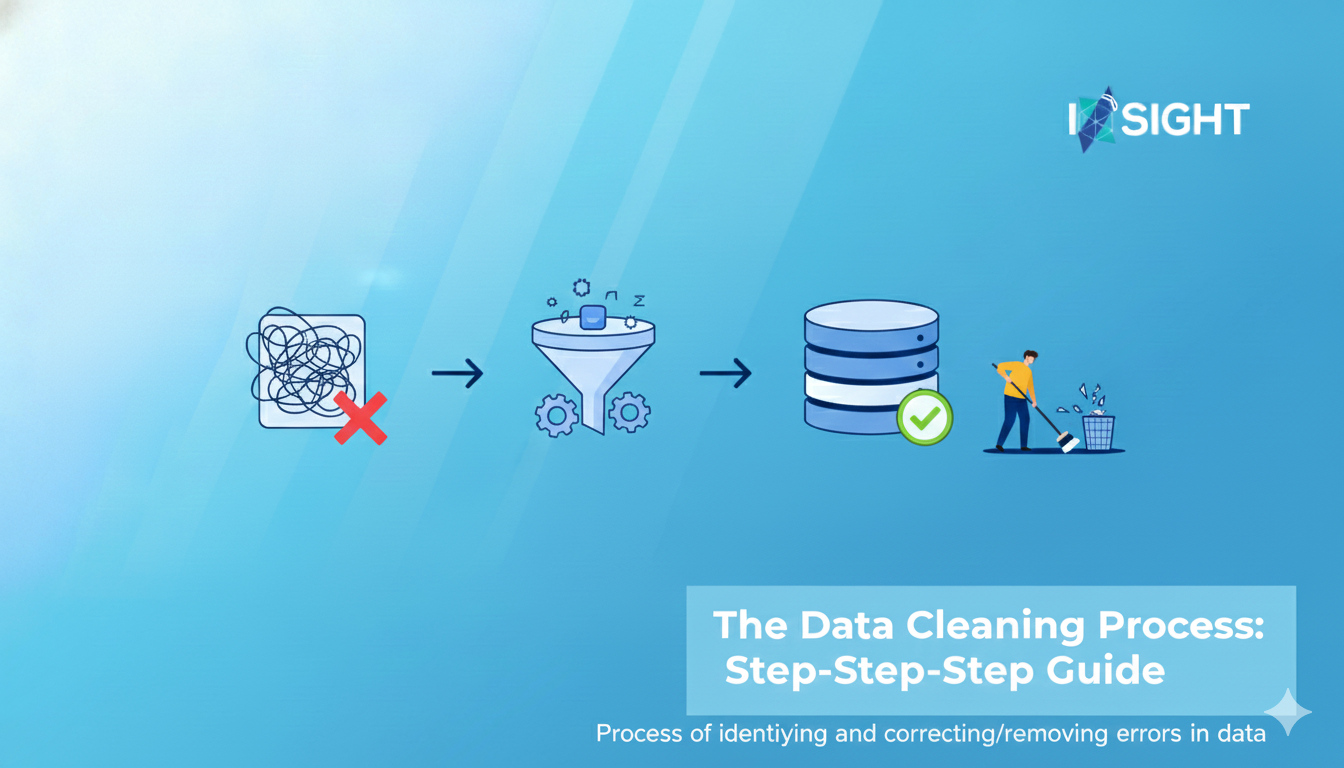
The data cleaning process is a structured, iterative workflow that turns chaotic raw data into refined gold. In 2026, automation via data cleaning software has shortened cycles from weeks to hours, but understanding the fundamentals remains crucial. Here's a seven-step blueprint, informed by best practices from IBM and Gartner.
Begin with exploratory analysis to map the dataset's landscape. Tools scan for nulls, duplicates, distributions, and patterns e.g., using Python's Pandas Profiling or AI-driven profilers in Alteryx. This reveals 80% of issues upfront, preventing downstream surprises.
Missing data affects 20-30% of datasets; decide on imputation (mean/median for numerics, mode for categoricals), deletion, or prediction via ML models like k-NN. AI tools like DataPure and Scrubbix excel here, inferring values from correlations.
Deduplication merges redundant records using fuzzy matching (e.g., Levenshtein distance for names). Outliers, detected via Z-scores or isolation forests, are scrutinised, errors get excised, and anomalies are retained for insights. This step alone can shrink datasets by 15%.
Uniformity is key: convert currencies, normalise text (lowercase, trim spaces), and align schemas. Regex patterns or NLP handle variants, ensuring interoperability across systems.
Cross-verify against rules (e.g., email regex) or external APIs (postal validation) - platforms like Scrubbix support this. Enrichment adds context like geolocation from IPs, boosting dataset depth without fabrication.
Reshape data via pivots, joins, or aggregations, integrating cleaned subsets into warehouses. ETL tools automate this for scalability.
The reproducibility is guaranteed by final audit using metrics (score higher than 95 in completeness) and documenting changes. Periodical screening is necessary as the data deteriorates at a rate of 30 per cent every year.
Issues such as scaling of big data or introducing bias still exist, but have been alleviated by data cleaning software that has no-code interfaces and AI recommendations. This process is mastered to bring 40 per cent efficiency improvements, according to 2026 benchmarks.

The market of cleansing in 2026 is flooded with choices, yet few of them shine when considering their ability to scale and smart automation alongside the actual ease of use. The top ten tools that analysts and even common users have been happy to recommend all the time after picking through the most current G2 crowd-sourced reviews, Gartner and Forrester reports, and actual real-world performance benchmarks are these.
The unchallenged leader in the eyes of the person who requires real-time, cloud-based cleaning when the data is coming in. This is a no-code giant that allows business administrators to create advanced ETL pipelines using straightforward drag-and-drop operations. It provides data masking, scheduling, and over 200 native connectors from all Salesforce to Snowflake. Its ease of use is also popular with teams, with even absolute beginners becoming live in hours, and the limitless usage plans eliminate the fear of receiving a shocking bill at the end of the month.
The company of choice when artificial intelligence and big scale cannot be compromised. Mammoth is designed by design and capable of supporting petabyte-scale workloads to detect anomalies, impute missing data, and watch over data quality in real time by using machine learning. In the no-code workflow builder, there is a sense of magic, and extensive connectivity to Snowflake, BigQuery, and Databricks makes it a dream for the analytics teams. The clean, modern interface is highly praised by users, though some of them state that the initial configuration of very complicated transformations may require some time.
The software that will ultimately turn Excel and Google Sheets into a part of the future. This intelligent AI extension allows cleaning and transforming data through plain-English requests: standardize all phone numbers, remove duplicate leads, or extract sentiment out of these comments. It does unstructured text, bulk normalization, and merges duplicates with frightening precision without having to get through your spreadsheet. The people who live in Sheets and are marketers, sales operations people, and analysts refer to it as life-changing.
This visual profiling masterpiece transforms the exploration of data into a visually beautiful experience. Its interactive charts and faceted browsing allow the hidden patterns to leap out of the screen, whereas the rule-based validation and deduplication can be performed with a few clicks. Teamwork functions and dozens of ready-made templates expedite the onboarding of whole teams. It is best in the light of profiling streaming internet of things information, or any source that comes in fast and untidy.
The business wrangling platform is somehow still easy to use. Guided AI proposes changes during work, interactive profiling identifies problems at an early stage, and in-built governance will ensure the auditors are pleased. It can be scaled easily to and past thousands of users and is flexible with low-code to handle the most complex pipelines. It is sworn by finance, operations, and advanced analytics teams. The compensation is a more difficult learning curve for complete novices and a starting cost of $4,950 per user per year.
It does not want to be an orphan in 2026. It is a privacy-conscious and privacy-controlling localization that provides strong faceted cleaning and name-variation clustering with an undo/redo history that grows infinitely. The community continues to add extensions, and since all of this happens on your personal computer, there are no charges to the cloud and no data-leak concerns.
The governance giant that is driven by the CLAIRE engine AI. When you work in a highly regulated industry such as banking, healthcare, etc, this is the language of compliance. It is the best in terms of rules reuse, integration of master data management, advanced profiling, and beautiful monitors. The very power that causes it to be adored by compliance departments makes it costly and sometimes burdened with resources, where its price may only be found by way of special enterprise bid-out-of-pocket quotes, or think five or six figures per year.
Data Ladder Data Match Enterprise is the fuzzy-matching expert that recruiters and sales teams gather at the feet of in order to purify sloppy contact databases. Its entity-resolution engine is capable of matching things that would require almost anything to match, and its address-checking and bulk processing capabilities can process millions of records with no problems. A free trial that is generously offered and one-time licensing as low as $995 has made it an option for smaller teams, although the interface is old by the standards of more recent cloud-native competitors.
the pay-as-you-go, serverless, and the pet of any person already in the AWS ecosystem. Building visual recipes, automated profiling, as well as gluing to S3, Redshift, and Lake Formation, allows Data-engineering and DevOps teams to stop spinning up to clean data. You pay literally by the hour of interactive use (about 1 per 100 hours), and therefore, it is unbelievably economical as far as a sporadic or seasonal workload is concerned.
The on-premise masterpiece is used when absolute data sovereignty is required by the organization. It is installed locally and provides automated validation, scheduling, and more intelligent deduplication, as well as retaining all the bytes within your own firewall. Small-to-medium-sized businesses that need sensitive marketing or customer information adore the one-time license plan, which starts at approximately $1000, and the fact that no recurring cloud billing is charged.
Also read: Data Cleaning: Definition, Benefits, Components And How To Clean Your Data
The unsung hero of the digital symphony of 2026 is data cleaning, which converts noise to harmony to make smarter and faster decisions. Since understanding what data cleaning is through applying the most effective data cleaning software, such as Integrate.io or Mammoth Analytics, or Scrubbix for contact and address data, preventive hygiene is the key to unlocking value. Dirty data should not put your path off track; audit your processes, fly a tool nowadays, and accuracy takes flight. You live in an information-saturated world, so you can't afford to have clean data; it is your superpower.
Ixsight provides Deduplication Software that ensures accurate data management. Alongside Sanctions Screening Software and AML Software, which are critical for compliance and risk management, Data Scrubbing Software and Data Cleaning Software enhance data quality, making Ixsight a key player in the financial compliance industry.
Our team is ready to help you 24×7. Get in touch with us now!